Michael Castelle
15th September 2018
This essay is based in part on presentations given in the Spring and Summer of 2018 at INRS in Quebec, the University of Chicago's Franke Institute for the Humanities, the University of Warwick Centre for Interdisciplinary Methodologies Research Forum, the Creative AI Meetup in London, and the Aarhus Institute of Advanced Studies. It is the first part of a longer argument, which is continued in a followup essay, “Social Theory for Generative Networks (and Vice Versa)”.
Introduction
The research area of deep learning undergirding the current explosion of interest in artificial intelligence is, as with many fast-growing fields of study, torn between two narratives: the first a familiar language of revolution and disruption (in this case with an added dose of born-again millenarianism), the other a more restrained (and sometimes dismissive) perspective which often uses as its foil the most hysterical proponents of the former. Are we at the cusp of a revolution in automation and “superintelligence”? Or are these techniques merely the temporary best-in-class performers in the present iteration of machine learning research? Alternatively, once these techniques are understood by a broader variety of thinkers, will there be a conceptual impact from deep learning in the social sciences and humanities? What will be its scale and scope?
In this essay, I will first describe some of my conclusions about deep learning (DL) from the perspective of a lapsed computer scientist (and former research programmer in neurology) who made a left turn — sometime around the beginning of the “Big Data” boom — to a more theoretical and historically oriented social study of science, knowledge, and technology. Then, I will draw the reader’s attention to some intriguing and currently-underemphasized connections between deep learning in practice and ideas from sociology, anthropology, and philosophy; in this I hope to show not just how social theory can inform the understanding of DL, but how an understanding of contemporary cutting-edge DL architectures can (somewhat unexpectedly) inform a more technical reader’s comprehension of abstruse social theory.
Like others before me, I am hoping (against hope) that a synthesis of reflexive social-scientific and humanist thought with the rather technical consciousness of our contemporary AI “arms race” can encourage the development of what Phil Agre called a critical technical practice — “a technical practice for which critical reflection upon the practice is part of the practice itself”. Agre’s essay on this topic is in the lineage of both Hubert Dreyfus’ infamous Heidegger-influenced AI critique and Lucy Suchman’s work at Xerox PARC on planning ideologies in AI; it explains how he came to see the “self-contained” AI field as “a powerful force for intellectual conservatism”, but saw a engagement between both technical and critical perspectives as potentially more rewarding and productive.

Texts in the ‘Critical AI’ tradition: Dreyfus (1972); Suchman (1984); Agre (1997).
The extended version of Agre’s argument, the 1997 book Computation and Human Experience (pictured above at right), was in part a critical commentary on what came to be known as Good Old-Fashioned AI (GOFAI), a programme focused on symbolic representations of “rules” and “plans”. In the late 1980s, the connectionism of artificial neural networks experienced a moderate resurgence with the publication of Rumelhart and McClelland’s “Parallel Distributed Processing” (PDP) volumes, but remained largely subordinate to the dominant AI discourse of Agre’s Ph.D. program at MIT. Today, the tables have dramatically turned, and the marginalized contributing authors of those volumes have become walking legends of a new 21st-century AI programme centred precisely on the absence of symbol-centered cognition, and instead the presence of so-called “deep” neural networks: multilayered hierarchies of a mix of linear and nonlinear transformations of primarily image, text, speech, and sound data. This paradigm is largely seen by its practitioners and others as a paradigm-altering scientific revolution (in the sense of Thomas Kuhn’s Structure of Scientific Revolutions):
- “Deep learning is nothing short of a revolution…” (François Chollet, 2017)
- “Just as 100 years ago electricity transformed industry after industry, AI will now do the same.” (Andrew Ng, 2016)
- “Deep Learning waves have lapped at the shores of computational linguistics for several years now, but 2015 seems like the year when the full force of the tsunami hit…” (Christopher Manning, 2015)
But at the same time, deep learning is also considered to be akin to “black magic”:
- “The general feeling is that deep learning is still by and large “black magic” we know it works, but we do not truly understand why” (Ronen, 2017)
- “[Deep learning] is still a black art” (Eric Schmidt, 2017)
I would argue that there is nothing currently better suited to investigations by social scientists interested in the study of knowledge than a present-day, self-described scientific revolution which is also portrayed by some of those same actors as related to medieval magic, and which in turn is also deeply imbricated in our everyday social interactions. One can get a quick look at the genuinely explosive growth in publications by looking at a descriptive analysis by the UK non-profit Nesta, which scraped the popular preprint repository arXiv.org:
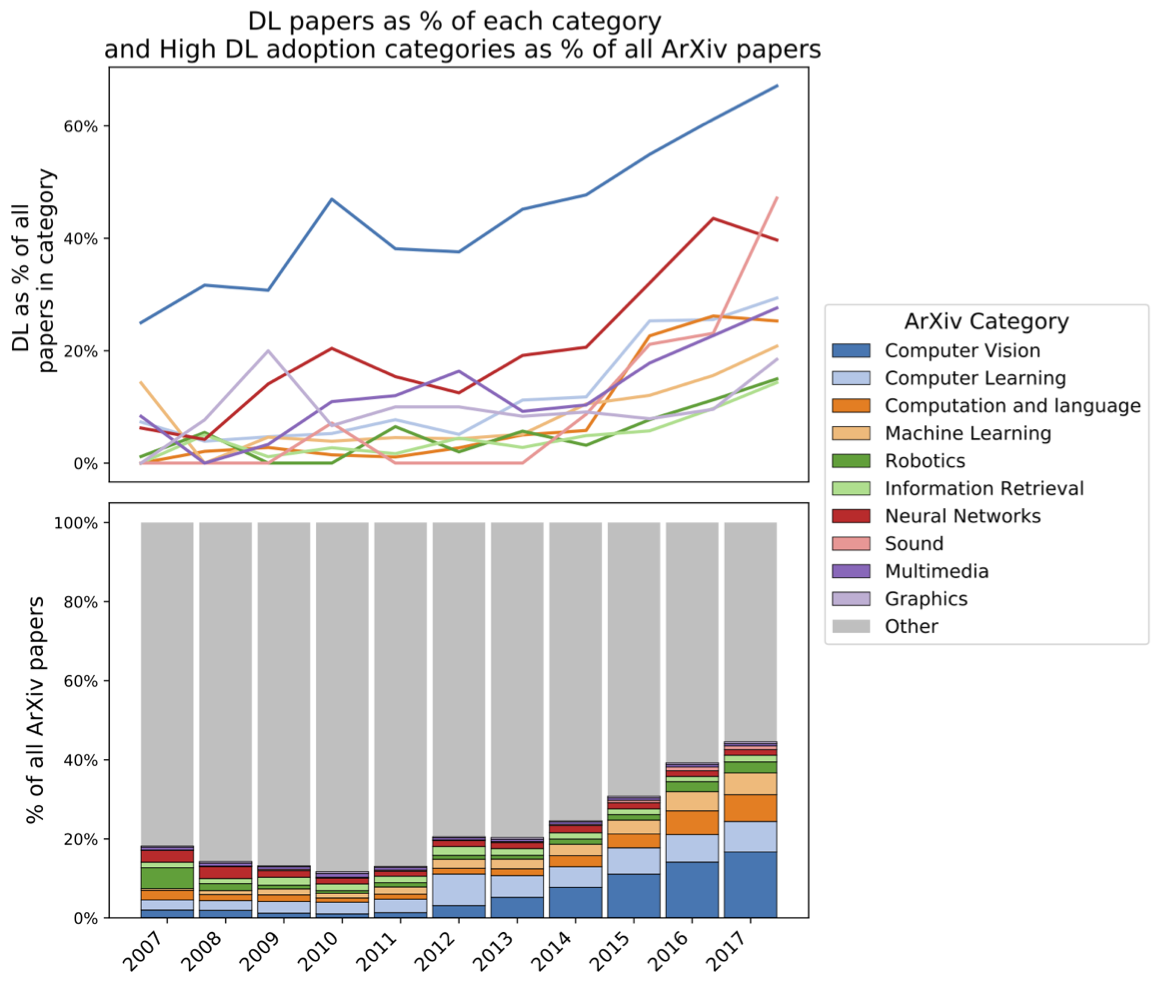
Deep Learning (DL) papers as a percentage of each arXiv category (top) and of all arXiv papers (bottom). Stathoulopoulos, Mateos-Garcia and Klinger, "Is AI eating software? An analysis of AI/ML research trends using scientific pre-prints", 19 April 2018.
We can see that there is an emphasis on vision/image data (for computer vision), sound, and multimedia over, e.g., information retrieval or robotics; computer scientists like to call that former kind of data ‘unstructured’ as opposed to the tabular representations of the relational database. (If there is an AI revolution going on, then, it seems intriguingly restricted to particular types of data representations; I will explore this in more detail below.)
Deep Learning as an Ensemble of Epistemic Breaks
But because deep learning, when viewed historically, clearly draws from a variety of existing scientific traditions, it doesn't necessarily make sense to view DL as a single paradigm-shifting revolution. Instead, I would suggest to view deep learning as an ensemble of paradigms, one which combines the outcomes of specific past epistemic breaks — by which I mean a kind of smaller-scale transformation in how knowledge is acquired in a given field. (The concept of an ensemble which — sometimes unexpectedly — provides better results than any single contribution will be familiar to machine learning (ML) practitioners, in the form of techniques like boosting or random forests.)
Specifically, deep learning’s methodology incorporates aspects of the following epistemic transformations which took place across in the 20th century:
- From introspectionism to behaviorism
- From behaviorism to cognitivism
- From GOFAI to connectionism
- From data modeling to algorithmic modeling
Behaviorism
Behaviorism, the dominant genre of psychology in the United States from around the 1920s through the 1950s most commonly associated with Pavlov and B.F. Skinner, is not often explicitly mentioned in connection with machine learning or deep learning, and yet it clearly shares certain methodological characteristics. Primarily, behaviorism is characterized by a stimulus-response (or “S-R”) approach; similarly, in supervised deep learning, one trains a model by (1) presenting ‘stimuli’ (e.g. batches of images) and (2) adjusting the model’s parameters based on how well its guesses match the correct ‘responses’ (e.g. labels).

B.F. Skinner and a pigeon.
In addition, the language of modern-day reinforcement learning is in an etymological lineage with the terminology of Skinner’s operant conditioning paradigm (where, instead of training arbitrary associations between stimulus and response as in Pavlov’s bell, behavior is learned by an agent through experiencing the consequences of taking particular actions.)
However, unlike today’s conflation of deep neural network models with an anthropomorphized (if ‘artificial’) intelligence, early-20th-century behaviorists were noted for their deliberate avoidance of words associated with what was to them an unobservable cognition (e.g. of ‘mind’, ‘thinking’, ‘intentions’, ‘schemas’, etc.)
Cognitivism
The cognitivist turn, then, is another part of the deep learning ‘ensemble’. While behaviorists restricted themselves solely to observable stimuli and responses in their training of e.g. rats and pigeons, deep learning — especially when its models are considered to be a form of ‘artifical intelligence’ — is also part of the tradition of cognitive science, characterized by an outstanding interest in the topic of mind; specifically, a simple metaphor of mind as machine which, in the 1960s and 1970s, developed as a simplistic analogy between the human mind and the then-fashionable information processing systems called computers.
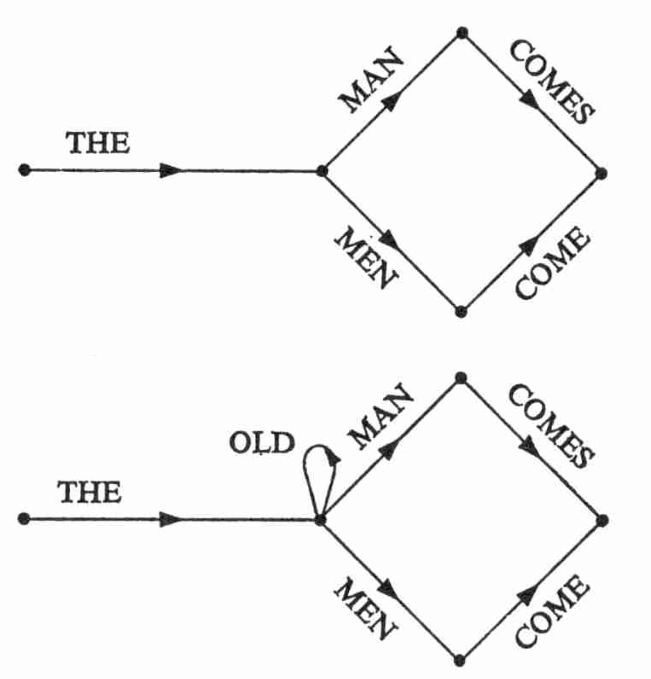
From Chomsky's "Syntactic Structures" (1957): Human language as a finite state machine.
Cognitivists like Chomsky, for example, spawned surprisingly productive fields of study by positing, for example, that ‘language’ was the product of a module isolated in the brain; and in which, e.g., “[it] is reasonable to regard the grammar of a language L ideally as a mechanism that provides an enumeration of the sentences of L in something like the way in which a deductive theory gives an enumeration of a set of theorems.” The reductionism involved here is not only dualist (segregating mind from any kind of physical embodiment) but individualist (‘language’ is seemingly unrelated to social interaction).
The world of machine learning, in which relatively-disembodied mathematical models are trained on a static corpus of stimuli and make decisions independently of each other, is thus also implicitly in this (dualist and individualist) cognitivist tradition.
Connectionism
However, cognitivist perspectives in the 1960s and 1970s, inspired as they were by the digital computers of the era, were largely oriented towards symbolic views of the mind, i.e., of the rule-based manipulation of arbitrary symbols. This belief was a core doctrine of so-called “good old fashioned” artificial intelligence (GOFAI) research, but was problematized by the recurring emergence of connectionist (or sometimes subsymbolic) approaches of artificial neural networks. These connectionist strategies were initially inspired by the views of the neuropsychologist Donald Hebb, who argued that neuronal ‘assemblies’ could be organized through experience via the modification of synaptic transmission.
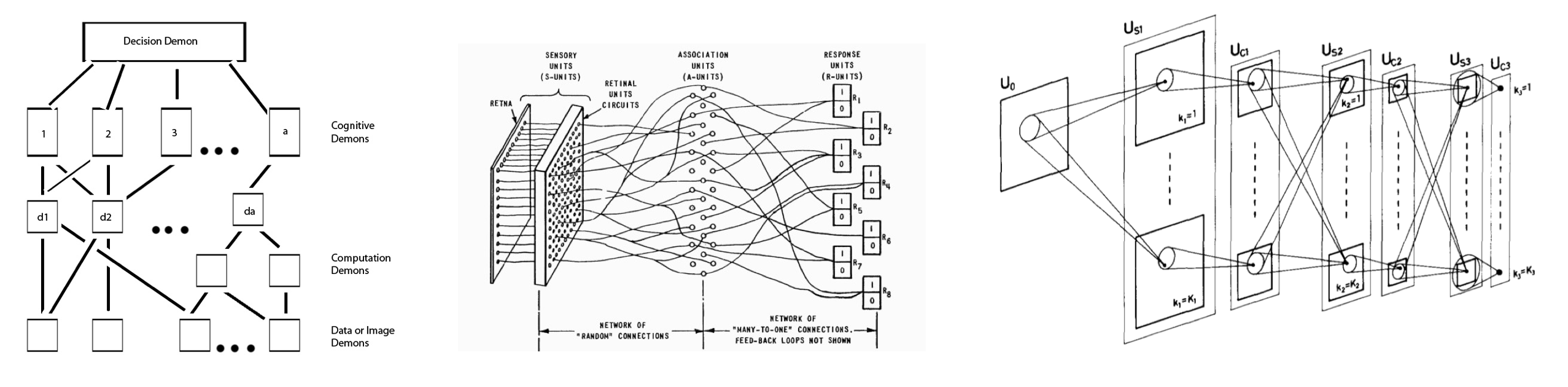
Selfridge’s Pandemonium (1958); Rosenblatt’s Perceptron (1960);
Fukushima’s Neocognitron (1980).
Early hierarchically-organized learning systems like Selfridge’s Pandemonium and Rosenblatt’s more explicitly neurologically-inspired Perceptron (above) were designed for the goal of pattern recognition, to discriminate between, e.g., different letters of the alphabet; and thus they are of significant historical interest from the perspective of today’s deep learning techniques, which also use as their functional baseline the discrimination of characters (specifically, the dataset of handwritten digits known as MNIST.)
Because an embrace of connectionism necessitated a partial epistemic rejection of strictly symbolic approaches, the two views battled it out over periods of decades: after Minsky and Papert’s then-convincing 1969 dismissal of connectionism, symbolic AI became definitively dominant, and interest in pattern recognition tasks receded; 20 years later, with Rumelhart and McClelland’s PDP volumes (mentioned above), symbolic AI entered its “winter”. This mid-1980s wave of connectionism then declined yet again in the mid-1990s with the development of machine learning techniques like Support Vector Machines (SVMs) that, at the time, clearly outperformed neural network-based pattern recognition methods.
Algorithmic Modeling
Leo Breiman, in his 2001 article “Statistical Modeling: The Two Cultures”, describes SVM and other methods from the machine learning community as part of an 'algorithmic modeling' culture which privileges black-boxed predictive power over the interpretable model parameters of traditional 'data modeling' cultures (such as the logistic/linear regressions familiar to quantitative sociology and psychology), the latter of which make strong assumptions about the data-generating process. For Breiman, while academic statisticians remained largely beholden to this latter ‘data modeling’ culture, various industries (with their increasing volumes of “big data”) had moved on, embracing ML methods like random forests which often excelled at prediction without necessarily being easily interpretable.
The excitement around deep learning is, like the success of the algorithmic modeling culture, related to its performance in prediction; but (as I hope I have conveyed) it is more than just another data mining technique. Its distinctive combination of epistemologies and techniques (behavioral, cognitive, and connectionist) means that it cannot entirely be encompassed within Breiman’s arboreal world of algorithmic models, specifically when — unlike ML techniques which operate on tabular information only — it works on data with spatial or temporal contiguity, such as images, text, sound, and speech.
Deep Learning’s Distinctive Features
As it emerges from this epistemic brew, I see the distinctive features of Deep Learning as:
- Use of an ML-style paradigm of pragmatic prediction
- Arrangement of model’s weights in layers a staged pipeline of both linear and nonlinear transformations
- A vectorial representation of inputs and outputs per layer (as vectors, matrices, or higher-dimensional arrays)
- The use of a loss function (or objective function) which unidimensionally quantifies success of the model for a given input
- The use of an optimization process (or optimizer) to minimize the values from the loss function; thus, an algorithmic model whose parameters/’weights’ are determined processually.
- The use of large quantities of training data (frequently, but not always, drawn from human labor; cf. ImageNet vs. AlphaGo)
- Use of specialized “General-purpose graphics processing units” (GPGPU) hardware originally designed for graphics rendering
In this essay I will not address all of these qualities, but will discuss 3 of the most significant in turn — layers, vectorization, and loss.
Connectionist Layers (the ‘Depth’ of Deep Learning)
What is specifically significant about DL architectures is how they explicitly unfold in a flow of linear and non-linear transformations of information, which (via backpropagation) alternately fold and unfold, forward and backwards, in the process of training. While comparisons between these architectures and human neurological 'architectures' can (and should) be controversial, there is an intuitive appeal in modestly analogizing between the feed-forward flow of Yann LeCun's early-1990s digit recognition and the directional pathways of the visual cortex.
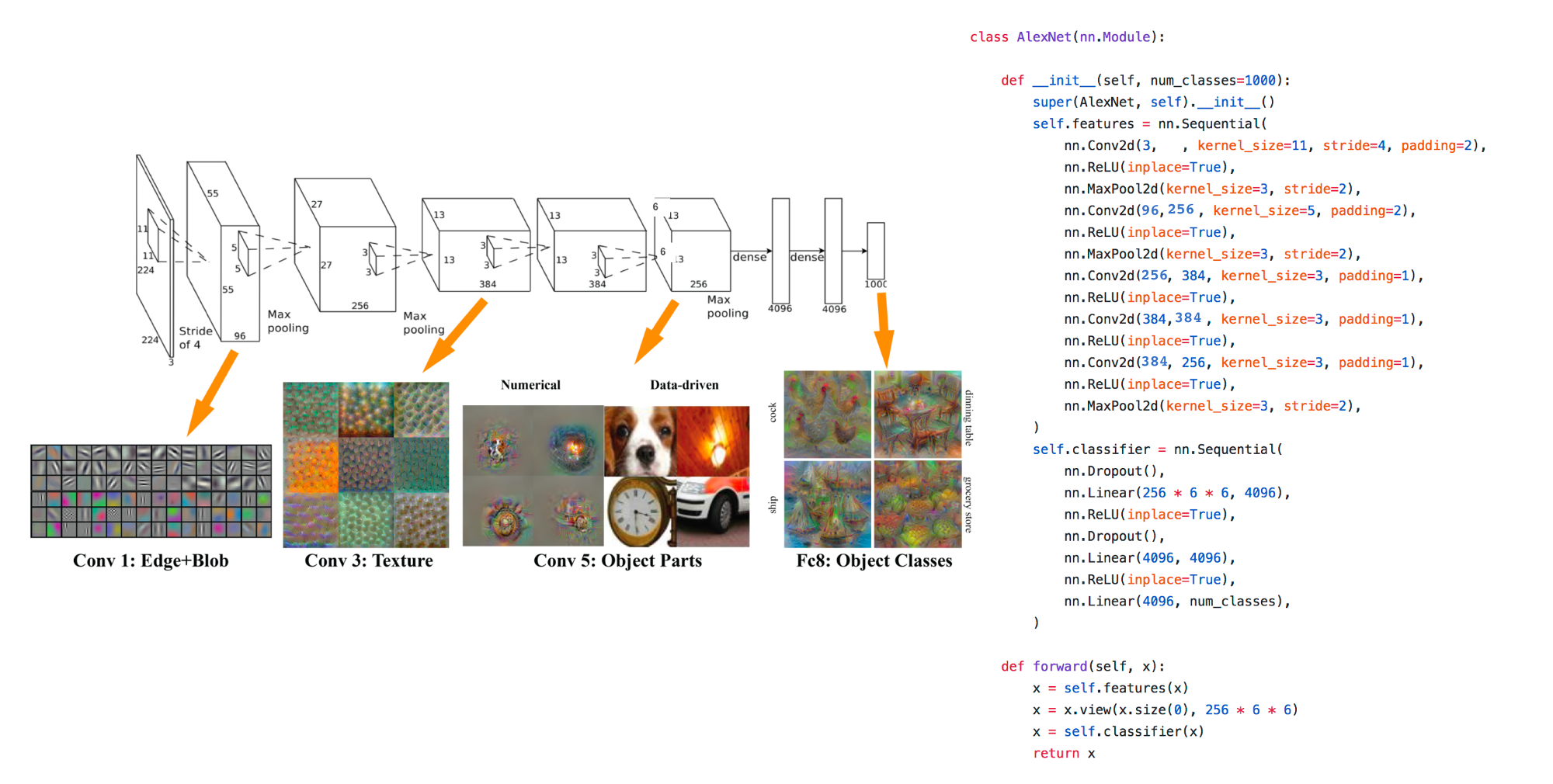
AlexNet (left) expressed in the DL library PyTorch (right).
This layered, hierarchical architecture most strongly distinguishes DL from traditional statistics and ML, in which a model's weights are most commonly represented as a list or vector of real numbers (as in linear regression or in SVM). Modern variants of Le Cun et. al.'s hierarchical models (such as AlexNet, trained on the crowd-labeled ImageNet corpus) can now be expressed in a very short amount of code (illustrated above). With some training, one can learn to interpret the above code as defining a sequence of linear convolutions (each similar to a 'Photoshop'-style image filter), nonlinear rectifications, and downsampling transformations, which ultimately provide a vector of predicted values between 0 and 1 for every object class in the training set (such as 'motor scooter', 'leopard', 'starfish', 'container ship', etc.)
Vectorization

In convolutional image classifiers based on the ImageNet dataset, training images, subsequent feature layers, and outputs are represented as multidimensional real-valued vectors.
Just as the widespread transformation of varied social activity into a bureaucractic database form (in the 20th century associated with Excel spreadsheets, the 'relational' model of SQL, and corresponding tabular strategies) is potentially problematic, the DL perspective offers some related, but slightly differing, constraints. Specifically, in the case of contemporary neural networks, all inputs, outputs, transformations, and intermediary forms must take the form of vectors, or fixed sequences of real-valued numbers. (A 2-dimensional vectorized form is conventionally called a matrix, and the higher-dimensional generalization of 'vectorized' linear transformations the tensor which, e.g., gives the name to Google's “TensorFlow” library for DL.)
We can see, then, why DL methods are immediately amenable to our digitized visual world, as images have long been represented as matrices of numbers (called bitmaps); “raw” digital image formats, for example, explicitly store separate 2-dimensional arrays of red, green, and blue values; formats like .gifs and .pngs are compressed versions thereof. Somewhat less obvious are the techniques by which DL models operate on so-called “natural language” text data; the most common methods here often involve assuming some kind of total vocabulary of lexical items (i.e. words) and associating with each word a distinct fixed vector of values; these are the word vectors, trained via an independent process on some large corpus of text data such as Wikipedia, and already appreciated as black-boxed carriers of human bias.
In the late 1990s, social scientists looking at quantitative practices described the growing and increasingly generalized activity of commensuration, a general transformation of qualities into quantities, used to facilitate simple numerical comparisons between otherwise complex entities; a simple example is the use (and abuse) of testing and quantitative evaluation in education. A culture of commensuration encourages educators to ordinally rank students (and flunk those associated with the lowest values), and for their managers to ordinally rank educators (and fire those associated with the lowest values), encouraging the formation of other institutions (cram schools, managerial consulting, etc.) to help “game the system”; by contrast, the effects of a culture of vectorization—in which social life and all of its features are transduced to matrix or tensor form for the purposes of AI— have yet to be fully explored (although see Adrian Mackenzie’s 2017 book, Machine Learners, for some relevant explorations of this topic).
Loss
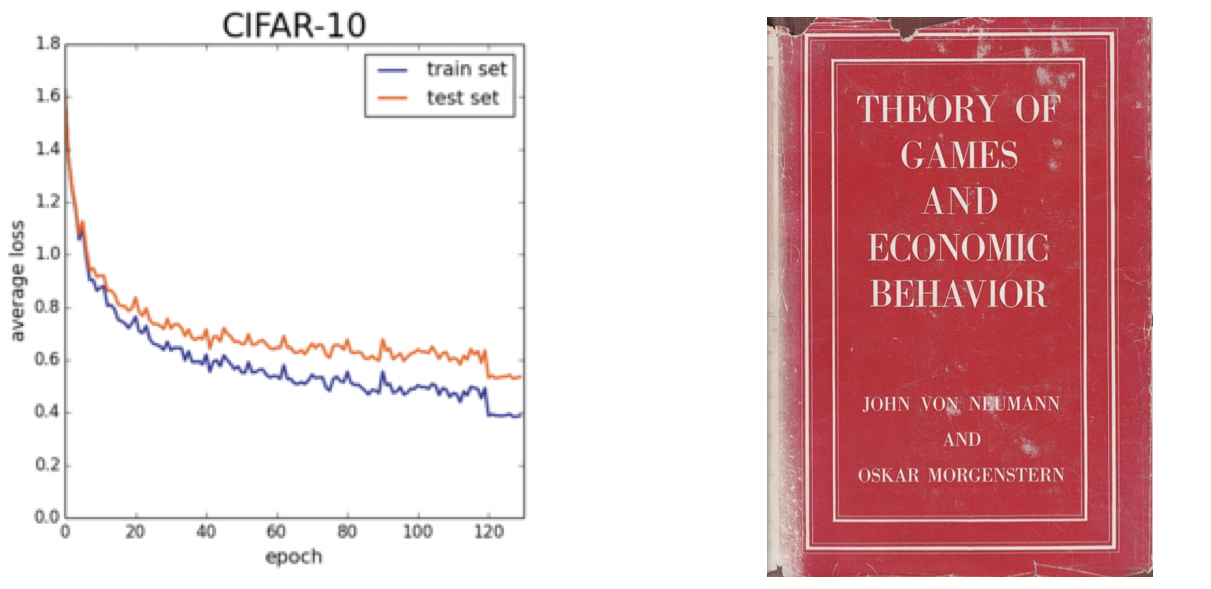
At left, practitioners training DL models consult graphs of a (hopefully) declining loss function on their training and validation sets. At right, the book by von Neumann and Morgenstern which popularized the view of economic behavior as a matter of utility maximization.
Finally, fundamental to training deep learning models is the concept of a loss function, a programmer-defined (and thus arbitrary) function which, in the case of supervised learning, gives a “distance” score for the model’s performance on a given labeled input. So, if an ImageNet model in the process of training is given a picture of a tiger and its output vector indicates that the image most likely contains a starfish (for example), the output of the loss function will be relatively high; and if the output vector correctly indicates that the image likely contains a tiger, that value will be relatively low.
The historical origins of the loss function are in the statistical decision theory of Abraham Wald, who proposed in the late 1940s that statistics should be seen as a special case of the game theory of von Neumann and Morgenstern, which was (and is) predicated on “the endeavor of the individual to obtain a maximum of utility”. It is not commonly recognized that when DL practitioners speak of models “minimizing their loss function”, it is, mathematically speaking, the additive inverse of the economists’ and game theorists’ language of “maximizing one’s objective function”. As such, to the extent that we might like to ascribe the term ‘intelligence’ to these models, it will be a kind of intelligence born of a culture of individualized, instrumental rationality. (This insight will become important in my discussion of generative networks in a follow-up essay.)
Conclusion
The result of this innovative bricolage of the aforementioned epistemologies with the distinctive features of techniques of layering, vectorization, loss optimization, human labor, specialized hardware, and more is — as we now know — to make possible not just the surveillance-state magic illustrated below, but also improved machine translation, super-resolution imaging techniques, and new forms of generative art.
Huang et. al. “Speed/accuracy trade-offs for modern convolutional object detectors”, CVPR 2017.
In my followup essay, “Social Theory for Generative Networks (and Vice Versa)”, I will show how DL’s particular ensemble of epistemologies, tools and techniques can, in the “generative” practices of the “Creative AI” community, be understood through the lens of varied humanistic and social-scientific thought of the 20th century, including Charles Peirce’s semiotics, the anthropologist Claude Lévi-Strauss’ theories of structuralism, and the sociologist Pierre Bourdieu’s conception of the habitus; but at the same time, I will implicitly suggest that social theory might itself be better understood and appreciated through the lens of deep learning.
Read Part 2 of this essay here.