Michael Castelle
28th September 2018
This essay is based in part on presentations given in the Spring and Summer of 2018 at the Creative AI Meetup at the Photographer’s Gallery in London, the University of Chicago’s Franke Institute for the Humanities, the Aarhus Institute of Advanced Studies in Denmark, INRS in Quebec, and the University of Warwick Centre for Interdisciplinary Methodologies Research Forum. It is the second part of a longer discussion about deep learning, the first part of which is in the essay, “Deep Learning as an Epistemic Ensemble”.
Introduction: Deep Learning, a Crisis for the Humanities

Opening paragraphs like the above — taken from a review of style transfer methods posted to the research preprint repository arXiv — provide some indication that there is a limited awareness of the intellectual waters into which deep learning is forcefully wading. Never before have such dramatic and intriguing developments in computer graphics, in my view, been accompanied by such minimal reflection on what art, images, creativity, aesthetics or style might actually be, or have historically been considered to be, in human societies. While many researchers clearly recognize that deep learning (DL) methods are most applicable to domains different from traditional data mining — a distinction usually expressed by reference to the so-called “unstructured” data of raster images, sound recordings, and text in contrast to the “structured” data maintained by relational databases — just as many are unprepared to accept connections between humanistic theories of signification and their own machine learning experiments.
Similarly, Mark Zuckerberg’s April 2018 testimony to the U.S. Senate reveals a misrecognition between his company’s ability to detect terrorist propaganda (perhaps identifiable by stereotyped iconography and particular keywords/phrases) and the potential to automatically detect online hate speech, which, according to Zuckerberg, his “A.I. tools” currently find challenging because of their “nuances”. From Zuckerberg’s perspective, with the right training data, specialized recurrent neural network architectures, and an appropriately-defined loss function, it will eventually be possible to efficiently separate the hateful wheat from the chaff. To believe this, however, is to mistake instances of abusive language — as perhaps computer vision practitioners mistake impressionist paintings — for artifacts whose meaningfulness exists independently of their social and interpretative contexts; and it is clear that as machine learning techniques and methodology become increasingly immersed in our everyday social and semiotic lives, ML/DL practitioners will come to need to recognize the relationships between their interventions and more complex understandings of aesthetic and linguistic meaning.
Peirce’s Semiotics

As such, I increasingly believe it would be helpful for deep learning practitioners to themselves understand those “nuances” of human communication and signification, beginning with the semiotic categories of icon, index, and symbol of the American philosopher Charles S. Peirce. As shown in the slide above, Peirce divides so-called sign-objects (the empirical manifestation of signs, independent of their interpretations by observers) into iconic signs, which refer via likeness; indexical signs, which refer via physical contiguity; and symbolic signs, which refer via an arbitrary relationship (such as the word “cat”, sustained within a particular English-speaking language community). Within this framework, we can see the photographs which have fueled so much DL innovation as sign-objects of a particularly intriguing sort, as they both can refer iconically (perhaps we recognize our own cat by a photo’s likeness) and indexically (analog photographic images are generated through a path from — to be brief — the alighting of photons onto reflective surfaces, into a refractive lens, colliding with silver halide crystals, to a chemical bath, to a physical print, and so they can be reasonably interpreted as referring to an observable situation in the past). As Rosalind Krauss succinctly put it in 1977, “The photograph is thus a type of icon, or visual likeness, which bears an indexical relationship to its object.”
In a way, the historical controversies of connectionism (explored at length in Margaret Boden's 2-volume Mind as Machine) can be understood as a debate between those cognitivists who believed the mind to be ruled by symbols (and formal logic and syntax thereof) and those who believed the mind was rather more indexical — as in a neural network, where inputs feed forward through multiple layers of “connections” to their outputs. (The symbol-centered ideology was indeed so strong that for a while connectionist perspectives were referred to as subsymbolic.) I would argue that many recurring wars in computer science can, in fact, be seen as unconscious debates about the social validity or appropriateness of differing semiotic theories; another important historical example would be that of CODASYL vs. the relational database.
Convolutions: Arithmetic on Proximate Pixels
Otavio Good,"A visual and intuitive understanding of deep learning",
September 2017.
The semiotic distinction between ‘iconic indexes’ (such as photographs) and symbols (e.g. written text) highlights how convolutional neural networks — in some sense which must be explained — are not quote-unquote “just math”; each weight layer of a convolutional image classifier, despite its ostensibly symbolic existence as a multidimensional tensor, represents a transformation which is still part of that indexical path (if a wholly ‘convoluted’ one, no pun intended) from photon to symbol (i.e. from a picture of some real-life lion to the word ‘lion’). This relatively reliable transduction from photograph to symbol, as realized by various ImageNet-based models, is at the origin of the contemporary excitement about ‘artificial intelligence’ — despite tasks of object recognition barely being seen as part of the early AI endeavour as described in the 1950s and 1960s.
This is to argue that because convolutional filters operate on regions of features which are logically close rather than far (i.e., on clusters of adjacent pixels), they can be interpreted as a kind of transformation which is not ‘purely’ symbolic and — especially in their layered realization as a processual flow — not ‘just algebra’ or ‘just math’ (to the extent that the abstractions of algebra do their best to elide the existence of the passing of time). This argument recalls Bergson’s debates with Einstein about special relativity’s spatialization of time, and following Bergson, we should see the reduction of sufficiently complex DL models to a simple, purely functional expression like "Y = F(X)" as phenomenologically offensive.
Word Embeddings: Symbols and the Spatialization of Sense
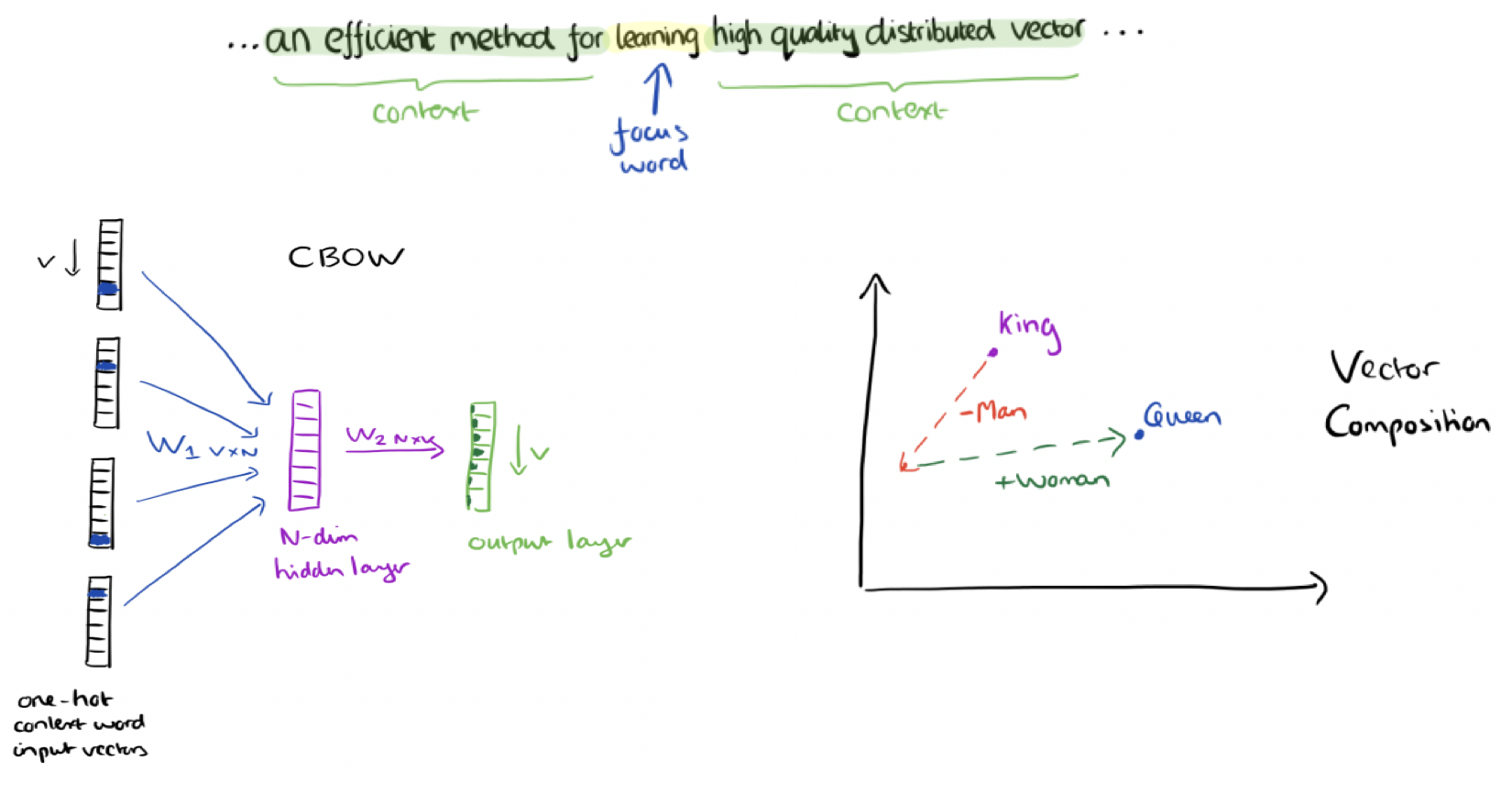
From Colyer (2016)'s discussion of Mikolov et. al. (2013)'s word vectors.
By contrast, it is not immediately obvious how one can apply these types of hierarchical models to textual, symbolic data. As mentioned above, the standard technique is to consider a large corpus of text (such as Wikipedia) and conduct a training process to project words into vectors of, e.g., 300 real-valued numbers. In the illustration above, we can see that word vectors are created by asking the question: can we predict the focus word given the surrounding context (really a strictly symbolic ‘co-text’)? The word2vec algorithm finds weights in a single hidden neural network layer to best answer this question; the resultant weights, taken row by row, are our ‘word embeddings’ or ‘word vectors’. These vectors famously appear to have intriguing semantic properties: if one subtracts the ‘man’ vector from the ‘king’ vector and adds the ‘woman’ vector, the resultant position is not far from that of the ‘queen’ vector.
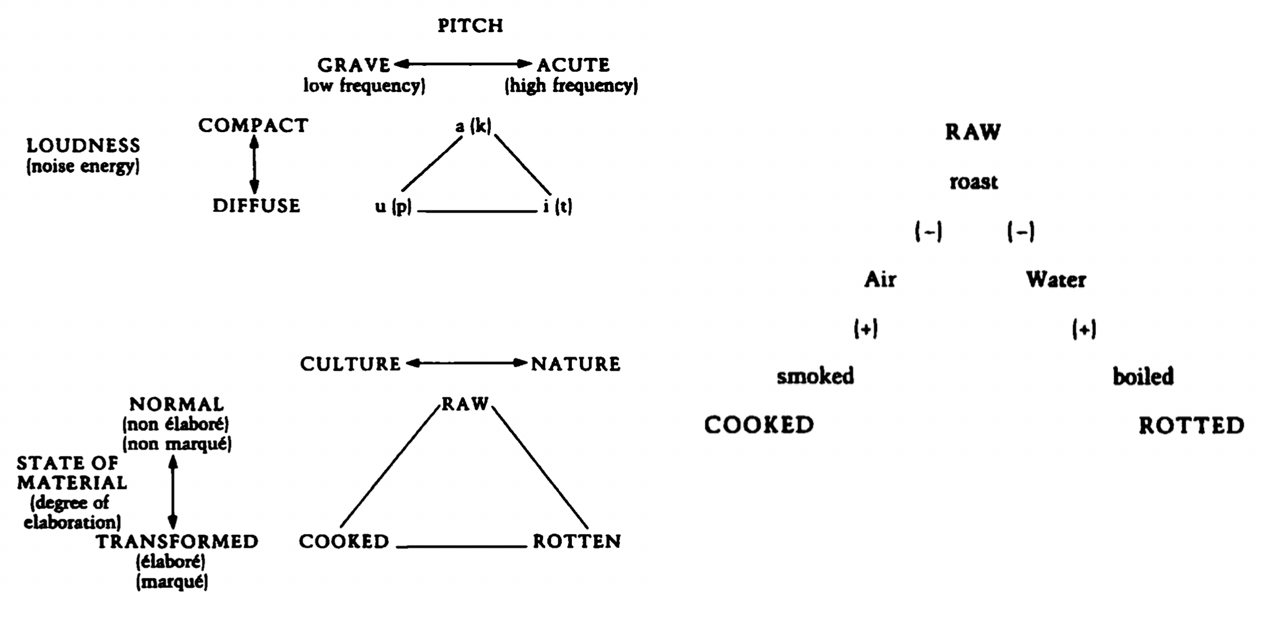
From Leach's book on Lévi-Strauss (1970).
The excitement around this kind of ‘semantic algebra’ quality of word vectors is, I argue, analogous to a different era of scholarly excitement: that of the 1960s intellectual project in the social sciences known as structuralism, as promulgated by the French anthropologist Claude Lévi-Strauss and Anglophone followers like Edmund Leach. Lévi-Strauss was inspired by two polymath thinkers whose modern-day descendants could not be further apart: on one hand, the information theory of Claude Shannon, and on the other, the structural phonology and poetics of Roman Jakobson. The former name is familiar to all computer scientists, and comes up surprisingly frequently in contemporary discussions of deep learning, while the latter lives on primarily in the domains of literary theory and linguistic anthropology. Lévi-Strauss was able to see that Jakobson’s systems of oppositions in phonology (such as the distinction between acute and grave vowels, or compact and diffuse vowels) could be thought of as the sets of simultaneous binary oppositions described by information theory. Moreover, he saw that questions at higher levels of meaning, going all the way up to the mythical narratives which produce and reproduce our cultural stereotypes, could be themselves productively analysed as sets of binary (or ternary, or otherwise enumerable) oppositions.
Word Embeddings as Folk Structuralism
Otavio Good, "A visual and intuitive understanding of deep learning", O'Reilly AI Conference, September 2017.
So when machine learning practitioners playfully visualize the ‘high-dimensional space’ of lexical meaning, as in the visualization above, I argue that they are articulating a kind of folk structuralism — a view that if we number-crunch culture in a sophisticated enough way, the ‘latent’ (read: ‘unconscious’) mathematical structures of our (secretly computational) minds will be uncovered. A modern-day Lévi-Strauss would likely not only embrace word embeddings, but push beyond them, and imagine a latent semantic structure not just of individual lexemes, but (in a suggestively ‘hierarchical’ way) incorporate both ‘lower-level’ phonemic structures and ‘higher-level’ poetic structures / mythical structures simultaneously.
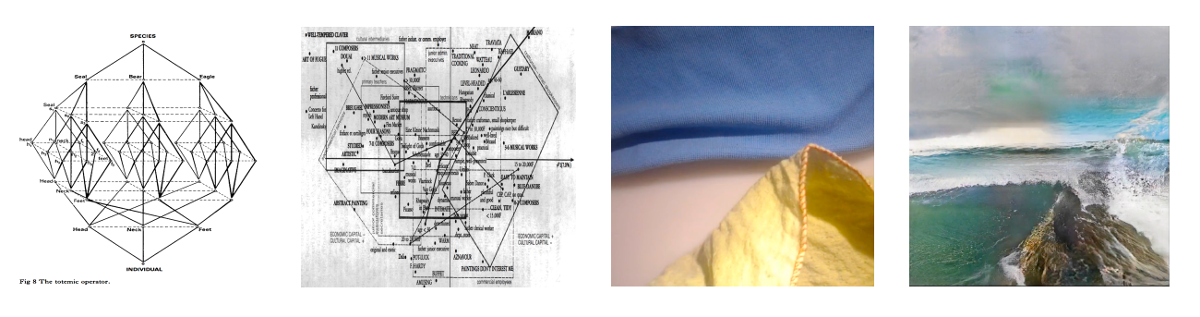
Lévi-Strauss, Classification, and ImageNet
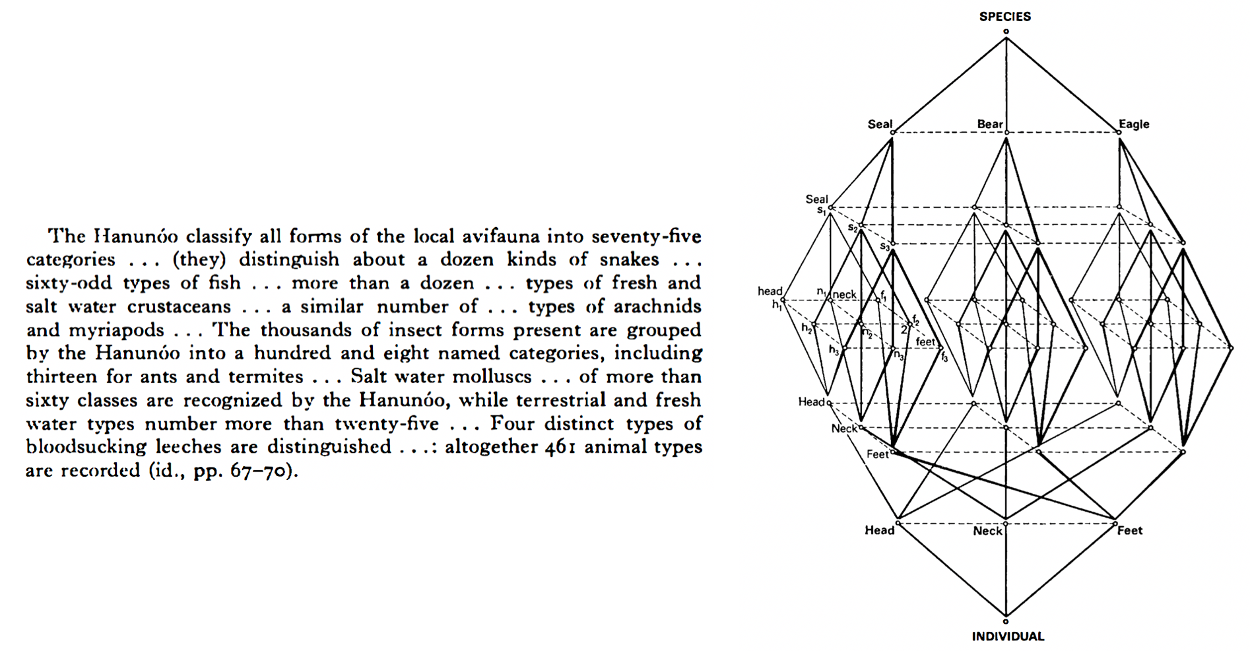
From Lévi-Strauss'
Interestingly — and analogously to DL practitioners who multi-modally move between text and image — Lévi-Strauss was not just concerned with hierarchical theories of cultural meaning, but was also interested in human practices of classification. In his famous 1962 work La Penseé Sauvage, he forcefully argued that the intricate classification systems of indigenous societies should not be considered any less coherent or logical than those of modern science, even if those classifications were ultimately deployed for different cultural goals. He was especially fascinated by the ways that these classifications of animals and plants were nearly universally projected onto the classifications of people (e.g. to use a simplistic example, the way individuals could be construed as members of the ‘bear’ or ‘eagle’ or other more intricately classified clans). In a way, his point was that these societies’ classification systems, drawn from empirical observation of their environment, consistently inform their apprehension and understanding of the world.
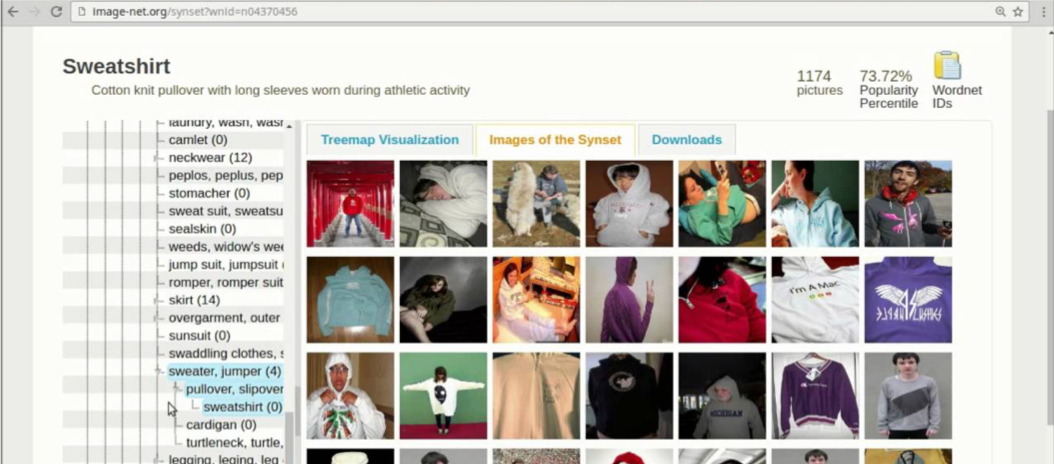
Examples of training images for ImageNet classes.
As such, we should have some immediate concern about the specific proliferation of trained models using the arbitrary classifications of, e.g., ImageNet, which — when deployed as artificial perceiving agents inside products of Google, Facebook, etc. — threaten to reproduce a very specific classification culture; one which is (for example) highly attuned to large numbers of species of dogs (producing the rather dog-centric artifacts in DeepDream), and whose concept of ‘volcano’ is, for example, rather touristic in nature (composed as it is from web-scraped photographs). It is not that the training data of ImageNet categories, which distinguish between ‘sweatshirt’ and ‘jersey’ are particularly iconic or indexical of capitalism, but in aggregate, they are symbolic of it.
Animations created with Plug-and-Play Generative Networks
explore the "latent space" of different ImageNet classes.
We should not be surprised if much of this covert symbolism is also somehow absorbed into social systems in often-imperceptible ways. When such symbolism is more literally explicit, it takes the form of the overt ‘bias’ which is now often ascribed to machine learning algorithms. But is there a way to connect this burgeoning literature on ML bias with the longer sociological tradition of studying the reproduction of social stratification and inequality?
Bourdieu’s ‘Habitus’: A Structuring Structure

From Bourdieu, P. (1977),
Outline of a Theory of Practice p. 72The French sociologist Pierre Bourdieu famously broke with Lévi-Strauss’ brand of arguably static structuralism with a focus on practice and the generation of action. Specifically, he spoke about both social classes and embodied practices as being maintained by systems of something called 'habitus' which is both cognitive and social. What is habitus, exactly? Most graduate students in sociology at some point are expected to struggle with interpreting the above, notoriously inscrutable Bourdieu quote, in which he defines habitus as “systems of durable, transposable dispositions, structured structures predisposed to function as structuring structures…”
If you want to know what this might have to do with deep learning, I suggest that you first (like those struggling sociology grad students) read the passage slowly and carefully. The seeming goal of the habitus is to both ‘structure’ and ‘generate’ both ‘practices’ and ‘representations’, “without in any way being the product of obedience to rules”; these representations are “objectively adapted to their goals” without presupposing some kind of conscious or masterful activity; and they are “collectively orchestrated without being the product of the orchestrating action of a conductor”.
I argue that certain aspects of this concept bear an interesting resemblance to connectionist practice: namely the absence of overt (i.e. symbolic) rules as well as the absence of an overarching ‘conductor’. But another aspect — the way that the habitus is simultaneously both a structuring classifier and a structured generator — bear a close resemblance to a particular form of contemporary AI: that of the generative adversarial network.
The Dialogical Quality of Generative Adversarial Networks (GANs)
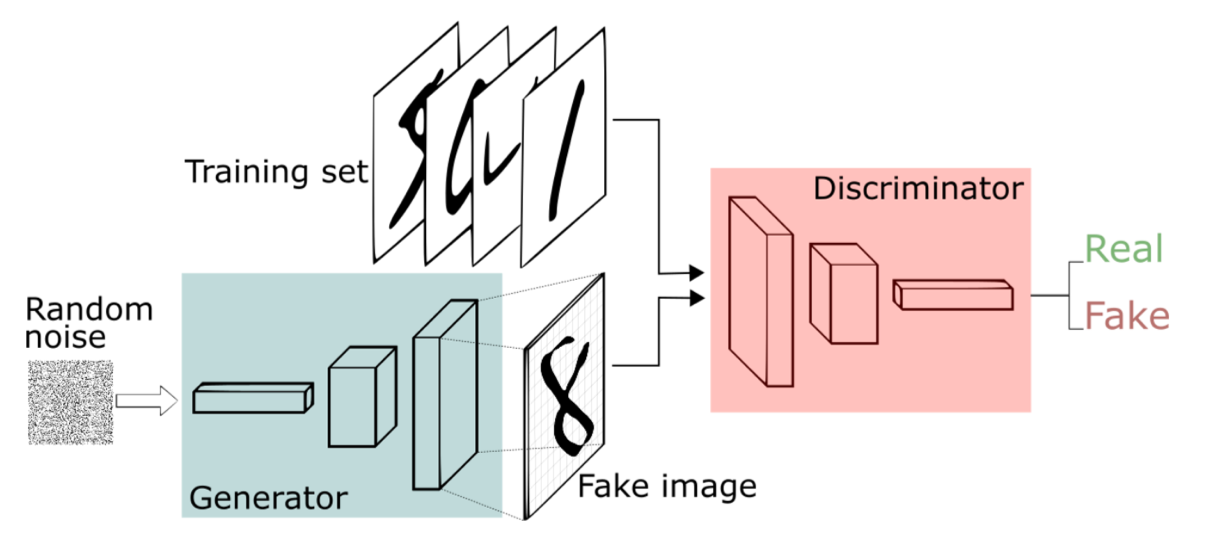
The architecture of a Generative Adversarial Network (GAN).
While the majority of deep learning research is focused on single neural network architectures, which begin with (say) an image stimulus and (through hierarchical layers of convolutional filters, downsampling, and nonlinear rectification) produce a prediction of the object class contained within the image, some architectures involve more than one such network. A prominent form of the latter is the so-called generative adversarial network or GAN, developed by Ian Goodfellow in 2014. Just as the habitus consists of structured classifications (based on past perceptions) and practical action, a GAN is composed of both a discriminator network and a generator network. In the process of training, the generator attempts to learn how to generate new images similar to the training data, but it learns this not from examining training data but from interacting with the discriminator, which (at the same time) is directly learning from labeled training data to recognize valid images (e.g. of digits, as in the animation below).
A generative adversarial network gradually learns to generate plausible digits.
The intriguing correspondence between GAN architecture and Bourdieu’s habitus theory has not yet been noted by DL practitioners, but it provides a helpful framework for understanding how GANs embody a certain type of learning — one which is not about rote memorization of hierarchies of patterns (as traditional supervised learning is often accused), but about acquiring understanding through practical action, in an environment with a ‘teacher’ who is perhaps just one step ahead of the student. For those less familiar with Bourdieu but more familiar with the learning theories of the psychologist Jean Piaget, we can see a similar correspondence in some of the latter’s claims, as quoted below:
“The principal goal of education is to create [people] who are capable of doing new things, not simply of repeating what other generations have done — [people] who are creative, inventive, and discoverers. The second goal of education is to form minds which can be critical, can verify, and not accept everything they are offered..." (Piaget, quoted in Duckworth 1969)
Instead, because of DL’s dependence on loss functions (discussed in Part 1 of this essay, Deep Learning as an Epistemic Ensemble), researchers currently view basic GANs as an antagonistic ‘minimax’ game, where the loss function of the discriminator (its ability to classify the training data) differs from the loss function of the generator (its ability to “fool” the discriminator into classifying its output as valid instances). Much as an intellectual dependence on game theory prevented 20th century economics from fully exploring the positive and negative externalities of social interaction (as well as the fundamental role of inequality in economic life), such a dependence can, for deep learners, potentially constrain the AI imaginary. I am proposing instead is to see GANs as the material beginnings of a potentially productive metaphor for the Bourdieusian reproduction of social structure: a mechanism through which the ‘bias’ in machine learning can map onto the ‘bias’ experienced in everyday cognitive and social life.
Towards More ‘Social’ Generative Networks
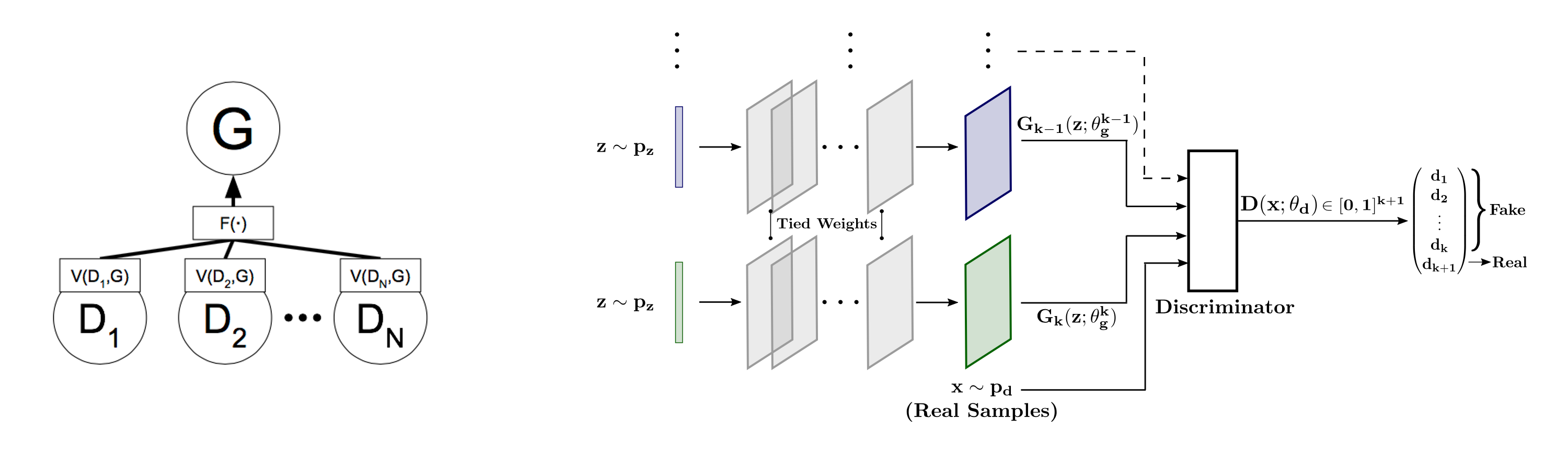
At left, "Generative Multi-Adversarial Networks" (Durugkar et. al. 2017) uses one generator and multiple discriminators. At right, "Multi-Agent Diverse GANs" (Ghosh et. al. 2017) uses multiple generators and one discriminator.
Despite this arguable misrecognition, researchers are gradually developing seemingly more ‘social’ generative architectures, which combine more than one generator, more than one discriminator, or both. For example, the diagrams above are from recent papers which modify the basic GAN architecture to have more than one discriminator (left) or more than one generator (right) in an attempt to improve training stability. This latter scenario can be metaphorically compared to, for example, the environment of a student art critique, in which the artwork of the student is simultaneously judged by both their peers and by a superior; in such a situation, the future output of the student is thus informed by a wider variety of signals.
Zhu et. al., "Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks", 2017.
Similarly, the architecture known as CycleGAN, pictured above — which can be used to translate images of a horse into that of a zebra, and vice versa, without being provided explicitly-paired training data — is constructed precisely as a pair of generator-discriminator dyads whose loss functions themselves interact: the aggregate model learns to generate zebra images from horses in tandem with its learning how to generate horse images from zebras. It is interesting to see the extent to which (in a computer vision conference Q&A) the model’s authors cannot entirely explain the impressive results of this model; they also describe manually modifying the loss function in order to steer the model into more expected directions (i.e. not spuriously changing a daytime Monet painting into a nighttime scene when the goal is to render the painting like a photograph).
Creative AI and the Habitus
Mario Klingemann experiments with a GAN trained on portrait paintings.
In the burgeoning ‘Creative AI’ community of artists who explore the use of DL research outputs as tools for artistic expression, the experimental work of Mario Klingemann, above, is a compelling (and dynamic) illustration of the conceptual overlap between generative networks and Bourdieusian notions of dispositions developing through generative interactions with past, structured situations. In his experiments provoking a neural network trained on a corpus of “Old Masters” portraits, the generator desperately strives to see faces — and, indeed, a particular genre of unsmiling white faces, at that — out of the complex input of everyday life. (“Old masters”, indeed; as Klingemann puts it in an interview, “By accident I do political art”.) The anthropologist Paul Kockelman, in his essay “The anthropology of an equation: Sieves, spam filters, agentive algorithms, and ontologies of transformation” has also recognized this mutual dependence of our filters (which he suggestively denoted as ‘sieves’) and our perception through those filters:
“…we apperceive through our sieves as much as we sieve through our apperception. We appersieve, if you will… In some sense, all sieves are inverses or even shadows of the substances they sort. By necessity, they exhibit a radical kind of intimacy.” (Kockelman 2013)
Conclusion: Bourdieu, Art Worlds, and the Limitations of Loss
Memo Akten, “Learning to See”, 2017.
In relation to this detour into the topic of Creative AI, it’s worth pointing out that Bourdieu also often focused on analyzing the social organization of artists past and present; artists were of interest to him in part due to their sometimes-characteristic antagonism for the norms of utility maximization associated with economic capital (e.g. that of the proverbial “bohemian”).
This perspective would suggest that if one ambitiously attempted to train a genuinely ‘creative’ AI by building a kind of simulated “art world” composed of a community of generative networks — a neural analogue of creators, peers, teachers, critics, and audience intermingling with varied habitus in overlapping fields — one would certainly want to avoid a conceptual dependence on the game-theoretic metaphor of minimizing various loss functions, or at least accept that such a formalization can only take you so far. For if one takes the aforementioned historical link between loss and economic utility seriously (i.e. as in the work of Abraham Wald and its adoption by von Neumann and Morgenstern), then conventional deep learning models may at present be fundamentally against the essence of art:
“The game of art is, from the point of view of business, a game of ‘loser takes all’. In this economic world turned upside down, one cannot conquer money, honours (it is Flaubert who said that ‘honours dishonour’)… in short, all the symbols of worldly success, success in high society and success in the world, without compromising one’s salvation in the hereafter. The fundamental law of this paradoxical game is that there one has an interest in disinterestedness: the love of art is a crazed love [l’amour fou], at least when one considers it from the viewpoint of the norms of the ordinary, ‘normal’ world put on to the stage by the bourgeois theatre.” (Bourdieu 1996)
Unsurprisingly, one research challenge of the past few years is how to metrically evaluate the performance of GANs, as their impressive ability to generate novel images or sounds is not as obviously quantifiable as the performance of a straightforward classification model. Given the links I have drawn between the history of loss functions, the architectures of generative networks, and the sociological perspective of Bourdieu, I would suggest that the difficulty in providing this kind of commensuration is associated with the limits of our ability to formalize what Bourdieu called the habitus; and so, thinking inversely, one might consider understanding DL models (and especially GANs) by thinking more deeply about the process of evaluation in actual art worlds (and in everyday life) — how it is so much more than a quantitative judgment by a single agent; and how the relative success of any work of art is highly dependent on the judgments of multiple members of more than one community, each with their own histories and biases, all mutually interacting with each other, in changing contexts, through the passing of time.
Thanks to the following individuals for discussions and suggestions: Ana-Maria Popescu, Etienne Ollion, Matthew Berland, Tyler Reigeluth, and Ye Tian. Thanks also to Luba Elliott, Memo Akten, Jake Elwes, and all the other participants and speakers at the London Creative AI Meetup.